
(Some of my hintervision thoughts are posted elsewhere. Here is an article from our Cloud Engagement Hub publication on Medium)
By Greg Hintermeister and Eric Herness
Application modernization business value can be calculated by measuring the specific impact modernization has on a number of behavioral variables.

Introduction
In working with dozens of clients this past year, we at the Cloud Engagement Hub started refining how we can more quickly help clients calculate the holistic, end-to-end business value of modernizing their applications. What we found is that while past conversations focused on cost savings found on a financial spreadsheet (infrastructure savings, licensing savings, etc), our Cloud Engagement Hub conversations with clients included many other aspects, including development, deployment, and operational behaviors that are altered when an application is modernized. A lot of these aspects can be measured with great accuracy since they are done today in more traditional forms, and equally as measurable after an application is modernized.
The following describes our current progress on how we calculate business value of modernization by measuring (or projecting) changes to many standard variables clients measure every day.
Our goal is to show that working with IBM to modernize applications isn’t a technical experiment, isn’t a science project, but is a solid business decision that will provide a visible return on investment, and will improve revenue in tangible, measurable ways.
Further, by focusing on variables that clients are familiar with, we can set up dashboards to provide real-time weekly progress on the value they are achieving…where based on these facts, can push their teams, or IBM, or both, to achieve the business value they deserve.
As you study this, provide any feedback in the comments. We’d love to discuss this in depth with you.
Variables Used
These are the variables in our pragmatic approach to calculating modernization business value. Each can be measured individually. The idea is that they should be measured before App Mod, and then either projected or measured after App Mod. They should be calculated for the level of modernization you choose: Containerize, Repackage, Refactor, Externalize. Based on your target, the variables will hold different values. The goal is to obtain the change of these variables; the delta. The delta will then be used in the formula to calculate business value.
Note: For some clients, not all variables are relevant. That’s OK. If you don’t have a way to measure, or don’t some of variables will change much when doing App Mod, then leave the change as zero.
Time-Based Behavioral Variables
These time-based variables can be divided into two categories: Development Focused, and Operations Focused. I know…a true DevOps environment doesn’t separate the two, but most enterprise shops are on a transformation journey and many still separate dev and operations.
As will be described in the details section, to calculate these variables, think about the tasks you perform, how many times you do each task, and what it would mean to automate these tasks.
Development Focused:
- Provisioning (P) Time to stand up dev/test environments (clusters, middleware, pipeline, etc.)
- Deployment (D) Time to deploy new app instances on an existing environment for dev/test
- Extensibility (E) Time to add new function based on user needs, market changes
- Testing (T) Time to test deployable units
Operations Focused:
- Provisioning (P) Time to stand up pre-production or production environments (clusters, middleware, pipeline, etc.)
- Deployment (D) Time to deploy new app instances on an existing environment for production
- Scaling Speed (Ss) Time to scale application to necessary levels to respond to demand
- Resiliency (R) Time to recover from a datacenter/environment outage
- Maintenance (M) Time to maintain running environments
- Time to Market (Tm) Time to deliver new revenue-generating feature to market
Cost Variables
- Infrastructure (I) Cost of Infrastructure (VMs, Bare Metal, Kubernetes Clusters) including what’s needed for ‘ready reserve’ for future scaling needs
- Labor (La) Cost of labor per unit of measure
- License (Li) Cost of licensing for app runtime/middleware
- Feature Revenue (Rf) Revenue of a feature / unit of measure
- AppMod Cost (Am) Cost to modernize to target level (containerize, repackage, refactor) multiplied by cost per unit of measure
Calculations
To calculate the business value, each element of the equation needs to be measured. Below, the elements represent the changes (delta) of each variable before and after modernization. If you don’t have the “after” measurement, the details section below will offer some suggested defaults based on real client feedback.
Time Saved in Modernization (Vt)
Vt is the aggregated time saved across all time-based variables above. The variables represent the App Lifecycle stages by containerizing, repackaging, or refactoring the application.
Vt = ΔP + ΔD + ΔE + ΔSs + ΔR + ΔM + ΔT
Costs Saved in Modernization (Vc)
Vc is the costs saved based on the time saved that was calculated above. This variable is simple the time saved (Vt) multiplied by labor costs per unit measured.
Vc = Vt · La
Feature Value (Vf)
Vf is the value of delivering a revenue-generating feature earlier due to the time saved modernizing the application. (Feature value) equals the time saved delivering a revenue-generating feature multiplied by revenue per unit measured. This should be run for every feature to reinforce that if a feature can be delivered 6 months early due to modernization, then future delivered features will see that benefit as well. It’s up to each client to determine how many Vf’s should be included into the final business value calculation. Generally, all planned features over the next two years should be used for accurate business value understanding.
Vf1 = ΔTm1 · Rf // Feature one, time saved with modernization, multiplied by estimated revenue of that feature
Vf2 = ΔTm2 · Rf // Feature two, time saved with modernization, multiplied by estimated revenue of that feature
Vf3 = ΔTm3 · Rf // Feature three, time saved with modernization, multiplied by estimated revenue of that feature
See the details section below for examples.
Calculate Modernization Business Value
Calculate the business value by adding all of the above together, then subtract the cost of modernizing the application itself.
Bv (Business Value) equals the costs saved with modernization (Vc), the infrastructure costs saved (ΔI), the licensing costs saved (Δli), The Feature Value for each planned feature (Vf), and then subtracting the investment to perform the target application modernization techniques (Am)
Bv = Vc + Vf1 + Vf2 + Vf3 + ΔI + ΔLi — Am
One final thought before we move onto the details: Since modernization moves the teams to an agile culture, many of these calculations should have a multiplier to reflect frequency. While teams may provision new environments today only once every 4 months, that may be because its too complicated. If it can be done in 2 hours, then there will be more than 3 provisions per year! There could be 100’s…magnifying the productivity of teams in the new, fully automated, agile culture.
Details: How to Calculate Each Variable
The following sections provide scenarios and suggestions on how we are working to obtain the changes of time due to modernizing the application.
Provisioning (P)
Definition: Time to stand up environments (clusters, middleware, pipeline, etc.)
Scenario: A development team needs an environment to enhance an application with a new feature. They need to stand up an application runtime, Db2, and MQ. This variable will measure how much time it takes from the initial request to when the developer can start working with that environment.
How to get measurements:
Simply asking experienced developers will give you a good estimate
- What is being provisioned, and how long does it take before you can use it? (DB, runtime (WebSphere), middleware instances (MQ, IIB, …)
- What is it’s purpose (Sandbox, dev, test, prod)
- Who needs to approve, authorize, manage the environments?
- What automation is used to provision?
It is quite common that a VM will take 2 weeks to become available for developers. While the actual provisioning can be done much more quickly, the approvals, validation, and exceptions result in most provisioning times to be measured in weeks, not hours.
Examples:
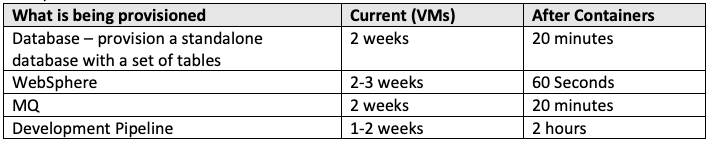
For initial estimates, the value of P would equal 6 weeks. If you don’t have an estimate for “After Containers”, then we can use these estimates or values from other client’s experiences we have worked with.
You will notice that you actually have two choices for estimating the delta: 1) effort to accomplish, or 2) linear time to accomplish. In the example above using the low-end estimates (and 8 hours per day), the time saved for provisioning would be as follows:
Before:
- Effort to accomplish: 7 weeks (35 days, or 280 hours)
- Linear time to accomplish: 3 weeks (15 days, or 120 hours)
After
- Time to accomplish: 2:41 hours (assuming some manual authentication)
ΔP = 117.3hours of linear time saved per provisioning instance (even more “effort” saved!)
Deployment (D)
Definition: Time to deploy new app instances on an existing environment
Scenario: An application needs to be deployed onto an existing environment. A test team and support education team need to run a new instance of the application. The assumption is that development is complete, and the application components are ready for deployment.
How to get measurements:
Measurements for this can be gathered from asking devs/testers/operations teams
- When you get a request to add an application to an existing environment, how long does it take?
- What tools do you use to deploy applications?
- What configuration is required to connect the application to the dependent resources?
- What load balancing and network changes need to happen to get the application running?
In our experience, adding applications to VM-based platforms can take quite some time, whereas a containerized application, using kubectl apply deploy.yaml could take 1–2 minutes.
Examples:

Extensibility (E)
Definition: Time to add new function based on user needs, market changes
Scenario: Product leader defines a new capability to add to an existing application based on user feedback. This variable measures the time it takes to add that capability to a production application.
How to get measurements:
This is intended to measure the productivity of the development team when reacting to a customer request or problem. To get the measurement, it’s important to understand the developer workflow. Some teams may be in a modified waterfall with dependencies and approval boards, while other teams are sprint-based and deliver as soon as the content is ready.
Examples:

Scaling Speed (Ss)
Definition: Time to scale application to necessary levels to respond to demand
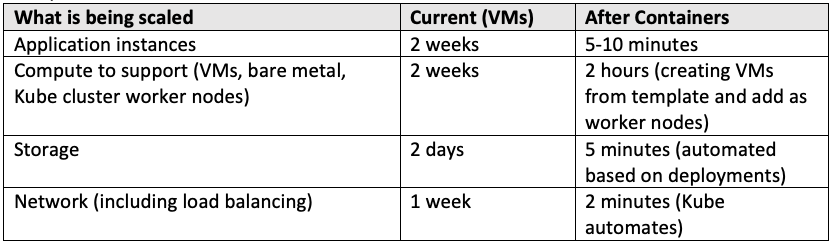
Scenario: As demand increases for an application, it needs to scale up (or down) to meet those demands. Additional compute, storage, networking needs to be added for additional instances. This variable will measure the time it takes to activate that scaling. For WebSphere JavaEE applications, scaling includes acquiring more VMs, add a node to a WAS cell, federate that node, then add a cluster member that lives on that node.
In the end, the expected value will be around what it takes to provision an environment and deploy an application (P + D).
How to get measurements:
This is measured because auto-scaling is not a reality for many applications. “Predictive scaling” is what many application and operations teams perform, predicting the demand, and setting up enough spare capacity to handle that additional demand, well before that demand appears.
To get the measurement, look to past events to see how long it took to set up the compute, storage, network, and application communication so that 3x-50x additional demand could be handled.
Examples:
Resiliency (R)
Definition: Time to recover from a data center/environment outage
Scenario: When an environment (or entire data center) has an outage, applications are obviously impacted, but the impact to end users is what’s most concerning. Current operations teams, regardless of technology used, have a resiliency plan to recover from an outage. Some operations teams go to great lengths to ensure applications running on older technology are resilient. Depending on your situation, you may want to measure a number of activities to come to your Resiliency number.
How to get measurements:
Here are questions you can ask your operations teams:
- (Server outage) How much time does it take to recover from a server outage to get the application back to its “normal” state?
- (Data Center outage) How much time does it take to recover from a complete data center outage to get the application back to its “normal” state?
There are a number of secondary questions that can add precision to this value. These questions revolve around how much time it takes to prepare an application for an outage so that the time to recover is near zero:
How much time does it take to prepare your application architecture to minimize downtime in the event of an outage?
- Are you replicating data to a secondary data center?
- Are you keeping the application up to date on a secondary data center?
- Are you keeping the that environment hot?
- Do you have load balancing that routes to multiple data centers/environments?
- How much detection/reaction of an outage is automated?
- How much infrastructure is in “ready but idle” state just in case of an outage?
The reality is that after containerizing some applications will still run as “pets” and need application-level synching while others, if architected for cloud, can run as “cattle” and be much more resilient. Either way, running in Kubernetes will automate many of the preparation activities, or at least make them far simpler. (Example: creating a Kubernetes cluster that spans data centers will make worker nodes run in multiple availability zones; greatly increasing application resiliency)
Examples:

Maintenance (M)
Definition: Time to maintain running environments
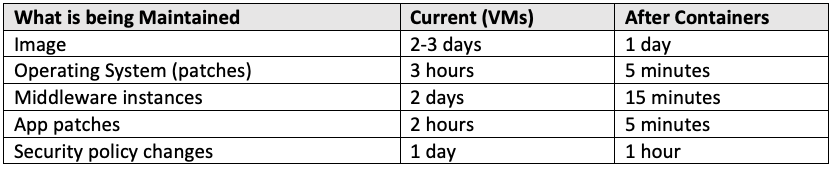
Scenario: An application has been running in production, and a variety of issues have been collected ranging from operating system patches, application defects, and middleware patches. The application team needs to maintain the running environment to comply with customer demands, regulations, and security policies.
How to get measurements:
This measurement is all about keeping the environment running properly in leu of patches, found defects, etc. As we all know, with existing VM-based applications (or bare metal), there are VM images to prepare, operating system patches to process, dependent middleware patches to process, application defects to fix and push out into production, changes in security policies to honor, and much more, depending on the application and depending on the company. Here is a list of examples to consider.
Note: The time here does not include development time to code a patch, only the time to push the patch into production.
Examples:
Testing (T)
Definition: Time to test deployable units
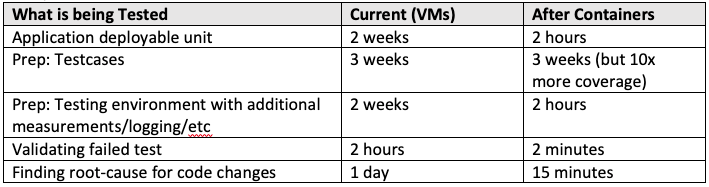
In traditional development shops, testing is general a separate activity. The move to cloud-native and a DevOps culture is primarily driven by test-driven development which make testing an embedded and natural element of the DevOps process. However, to get there takes effort and investment. This variable is to measure how long it takes to test an application unit before that unit is deployed into production.
Scenario: A test team receives a deployable unit to test for the next round of application enhancements. They previously provisioned the environment and have provisioned the application. Once testing has completed, the application moves to staging for additional integration testing, and finally to production.
How to get measurements:
This measurement is all about capturing the time it takes to fully test the deployable unit. In traditional cases, the deployable unit is the entire application, but once an app is modernized, the deployable unit is an individual container.
This is also capturing the time it takes to prepare for tests that require real-time feedback. While current platforms like Kubernetes log, monitor, and provide health checks for the container, many traditional environments required user interaction, break points, or exit points to achieve the desired scenario.
As a result, this “Testing” measurement is not only measuring time to test, but time to prepare and maintain the tests and the testing environments.
Examples:
Time to Market (Tm)
Definition: Time to deliver new revenue-generating feature to market
This variable is focused on “If you estimate you can generate $1M of revenue over a year, and by modernizing you can push out the feature 6 months earlier, you can achieve $0.5M in business value in modernizing that application for each revenue-generating feature”.
Scenario: A product team determines a new “visual recognition” system will generate $1M per year in additional revenue for their approval system. The dev team has created sprint plans across 5 dev teams to code necessary changes to the UI, backend, data systems, and new “visual generator” AI algorithms.
How to get measurements:
This measurement can be found by asking an application leader to sketch out this scenario and estimate how long it would take to deliver. Initially they would know “it will take one year”, and those skilled with Kubernetes, DevOps, and cloud-native architecture, could estimate as well “it will take us 6 months”
We also have existing client examples where they saw 30% speed increase.
Examples:

Infrastructure (I)
Definition: Cost of Infrastructure (VMs, Bare Metal, Kubernetes Clusters) including what’s needed for ‘ready reserve’ for future scaling needs
This is a basic measurement of infrastructure costs needed to support the application. No real scenario here is needed, just adding up all the infrastructure needed across Dev, Test, Staging, and Production.
How to get measurements:
Infrastructure costs vary greatly depending on the type of application. For this measurement, keep things simple and ask your IT teams:
- How many VMs does it take to run the application across Dev, Test, Staging, and Production?
One recent client we were at counted 23 VMs to run a fairly basic WAS/JavaEE application with the need of multiple environments, and resiliency, and scaling planning.
The “After containers” is a bit trickier. Obviously, it takes VMs to run Kubernetes clusters, so in some cases we bundle the applications to say “while it took 55 VMs to run these eight applications across environments, it only takes 20 VMs to run the same containerized applications across two Kubernetes clusters”. In this case, two clusters because many clients are fine combining Dev/Test/Staging into one cluster, but still want to keep production separate.
Finally, once your count is obtained, find the cost per VM and find the cost of infrastructure.
Examples:

Labor (La)
Definition: Cost of labor per unit of measure
This is a basic measurement of labor costs per day/month/year, based on the unit of measure the time-based calculations were in.
The goal here is to transform the time savings from the first set of variables to a numeric count.
How to get measurements:
List the different roles involved in the time-based calculations and their cost. This will vary based on role and if the labor is contractors or employees.
Also, there is no real “before/after” in this. Developer skills are precious so while some may see as “reducing labor costs” as a downsizing topic, it should be viewed as a way to make your skilled developers more productive.
License (Li)
Definition: Cost of licensing for app runtime/middleware
Modernizing an application can result in reduce licensing costs from a variety of sources, but accuracy in the calculations is essential. For example, some VM hypervisors have a higher licensing cost than others, but the lower licensed hypervisors may have higher support subscriptions.
How to get measurements:
Add up the number of licenses in use on VMs, and then the number of licenses of VMs running in containers.
Feature Revenue (Rf)
Definition: Revenue of a feature / unit of measure
This is an estimate of how much revenue a feature would add over a period of time. This is related to the Time to Market where you can determine “if a feature will bring in an estimated $1M over a year, and I reduce my time to market from 1 year to 6 months, I will have gained $500K in revenue”
Vf (Feature value) = ΔTm · Rf
How to get measurements:
This really comes from the product management team and the market team. This should be known before you are developing a major feature anyway, so should not be a lot of time to calculate.
Here’s what’s important: Even if your team only delivers a subset of the new feature in 6 months, that’s still revenue-generating content out in production faster. Think of it like paying for a loan every week vs. once every 6 months. The sooner you deliver, the more valuable your modernization becomes.
AppMod Cost (Am)
Definition: Cost to modernize to target level (containerize, repackage, refactor) multiplied by cost per unit of measure
This is estimating how much it will take to modernize the target application.
How to get measurements:
The estimating will vary based on the composition and complexity of the application. For JavaEE workloads, using tools like Transformation Advisor will provide a “xyz Developer Days” estimate based on binary scanning of the .ear and .war files. In addition, further analysis of Transformation Advisor’s findings will optimize the estimate to account for duplicate counting, etc.
The final variable should be the number of developer days for an application to be containerized, multiplied by the Labor costs.
Future Variables
There are three other variables to consider, but so far we are not including them because our goal is to focus on variables that can clearly be measured. Scaling Granularity was added as an initial variable, but it overlaps with other variables. One consideration would be to add a “Dependency (Dp)” variable to measure how much time a dev team’s enhancement/patch waits to be deployed so that a dependent team can update their code. Stability (St) is a measurement that we will add later since it will measure how people manually add Istio-like capabilities using traditional networking vs Kubernetes-specific capabilities like Istio.
• Scaling Granularity (Sg) Time to scale smaller components after repackaging apps to smaller, feature-focused containers
• Dependency (Dp) Time waiting for another team to commit their changes before your already-coded changes can be tested/deployed into production.
• Stability (St) Time to write automation to manually create circuit breakers, retry logic, advanced observability (BYO Kubernetes)
Summary
As you can see, while this is still a work in progress, we are quite excited to have the beginning of a framework to measure the business value of Modernization using the behaviors a Dev and Ops team currently uses, with the ability to measure time and cost savings as the application is modernized. To be honest, it’s also exciting to see that when this work progresses, the clients’ culture changes as well to a true DevOps organization…and that’s when savings really accelerate.
We’d love to hear your feedback…see you in the comments!