
(Some of my hintervision thoughts are posted elsewhere. Here is an article from our Cloud Engagement Hub publication on Medium)
The promise of Kubernetes with the ability to automatically schedule and scale your application deployments is enticing. But it’s not Magic! Making your microservices-based application automatically scale requires planning by both developers and cloud admins.
The concepts of auto-scaling are not unique to microservices, but what you need to know and understand is different. Developers need to contribute, as well as DevOps engineers, and certainly cloud admins to make auto-scaling successful. Some of that contribution comes by providing liveness and readiness probes in the app configuration, and the rest comes from knowing about the behaviors of each microservice and interactions between microservices.
This blog post will briefly introduce the concept of auto-scaling in Kubernetes. I’ll then follow with part 2, which will provide more concrete insights and supporting examples for specific languages and frameworks.
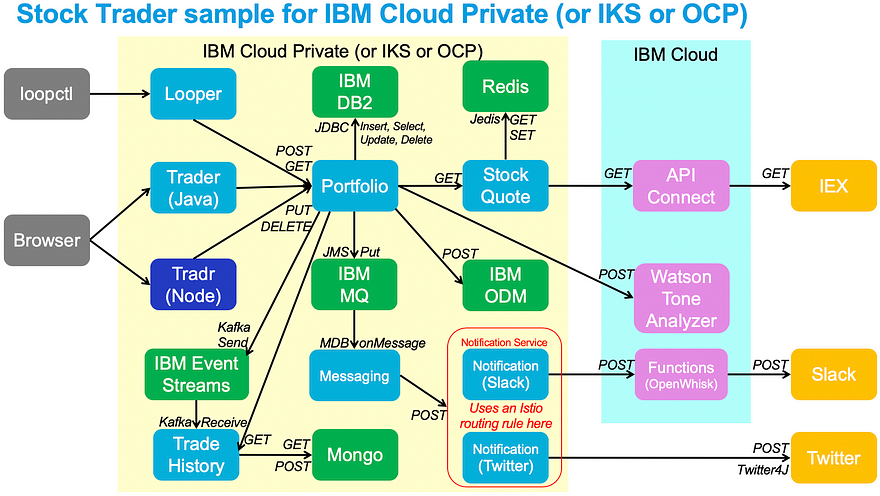
The following concepts need to be considered when you want to have your application scale in a Kubernetes environment:
Readiness and Liveness probes
Liveness and Readiness probes are essential because they let your microservice communicate to Kubernetes. The Readiness probe tells Kubernetes that the pod is up and ready to receive traffic. The liveness probe tells Kubernetes that the pod is still alive and working as expected.
The trick for the developer is to communicate meaningful status. In our example, if our “portfolio” microservice cannot connect to its data source, then the pod is not ready to receive traffic. The microservice may be up and kicking and in its own world quite healthy. However, since the portfolio microservice depends on the data source to set/get information, it will not want to receive traffic until it has an active data source connection. Once it is “ready”, it then checks for consecutive errors. If portfolio detects three consecutive errors for any communication, then the developer assumes there’s a problem and the pod should be killed and a new one started. Of course, each microservice may require a unique definition of “am I ready” and “am I living”.
Finally, while readiness and liveness probes are not required for auto-scale policies, they are essential so that the pods that are running are productive. Otherwise, the auto-scaler may detect 5 pods running under 50% utilization, but none of them are doing actual work. Timing is important, too. If the “readiness” probe says the pod is “ready” too soon, then work will be routed before the app instance is ready and the transaction will fail. If the “readiness” probe takes too long to say the pod is “ready”, then the existing pods will become overworked and could start failing due to capacity limits.
Readiness and liveness probes are mentioned again because your autoscaling needs to take into account how long it takes for additional pods to become available, and that a liveness probe that is too sensitive can cause your autoscaling to thrash needlessly due to pods being destroyed when they are not truly dead.
Resource requests and limits
Each microservice should specify how much resource (memory and CPU) is required to run. While not required to run in Kubernetes, these resource requests and limits are required for autoscalers to kick in. In Kubernetes, you will want to specify resource requests (how much CPU and Memory to allocate initially when bringing up the pod), and resource limits (the maximum CPU and Memory to allocate over time).
Here’s a sample that a deploy.yaml file would have to specify resource requests and limits:
Horizontal Pod Autoscaler
The Horizontal Pod Autoscaler (HPA) is created by attaching itself to a deployment or other Kube object that controls pod scheduling. In its most basic form, the HPA will look at all pods in a deployment, average the current CPU utilization across all the pods, and if the percent utilized is more than what the HPA is set to, then the HPA will provision additional instances. Conversely, if the percent utilized is less than what the HPA is set to, then the HPA will remove instances until the utilization is approaching what was desired.
Here I’m creating an HPA that attaches itself to the deployment called “portfolio”, and will scale the number of pods between 2 and 10, depending on if the average CPU utilization is above or below 50%.
Vertical Pod Autoscaler
An emerging capability in Kubernetes is vertical pod autoscaling (VPA), which means it can scale the resource requests / limits in real-time so an individual pod can take up more resource.
VPAs can be quite useful for applications that are not written to horizontally auto-scale. If it needs more resource then it can vertically scale. While the best practice is to architect your application for auto-scale, there are some cases where it is not possible and VPA is a good option.
Further, VPAs can be powerful companions to HPAs. For example: If I have an HPA provisioning new pods, it may come up against capacity limits for available worker nodes. In that case, a new pod will not be provisioned. This can happen when the Kubernetes scheduler fails due to affinity rules, resource availability for full pods, readiness probe indicating delay, etc). If you set a VPA to scale the pods vertically in that situation (give each pod 10–20% more CPU and/or Memory), then the existing pods could have some “breathing room” and grow with the small amount of resource still available in the worker node they’re running in.
Node Affinity, Taints and Tolerations
Node affinity, taints and tolerations allow users to constrain which worker nodes an application can be deployed to.
An affinity rule tells Kubernetes what kind of worker node the pod requires or prefers (you can think of it as “hard” or “soft” compliance). The affinity matching is based on node labels. This means that you can prefer that your pod runs on any of the 5 of the 50 worker nodes in the cluster that are labeled as “GPU-enabled”, and also require that the nodes run on any of the 20 of the 50 worker nodes labeled as “Dept42”.
To view the labels on a node, run kubectl get nodes -o wide — show-labels
Taints and Tolerations tell Kubernetes what kind of pods a worker node will accept. This means that a set of worker nodes can be tainted with “old-hardware” and only pods that have a toleration for “old-hardware” will be scheduled.
Think of it this way:
affinity is pod-focused: “I am a pod…there are so many nodes to choose from let me filter so I get one I will run well on”. Affinity lets the pod choose what nodes it will deploy into based on how the nodes are labeled. “I prefer new hardware nodes” “I require GPU-equipped nodes” and then Kubernetes will schedule appropriately.
Taints/Tolerations is node-focused: “I am a worker node…there are so many pods out there, but only certain ones will run well on me due to my unique traits…I will add a taint to require pods to declare that it will tolerate this unique trait”. Taints let the node declare “I am old hardware” or “I am only for production” and as a result, the Kubernetes scheduler will only deploy pods onto those nodes if the pod has a toleration matching that taint: “I am production pod” or, “I will run on old hardware”.
This is one reason why clear communication between development and cloud ops is essential.
Resource Quota
Each namespace in Kubernetes can have a resource quota. This is set up by the cloud admin to limit how much resource can be consumed within a namespace. As this is a hard limit (actual number, not percentage), once an application scales up to the quota limit, it will get a failure if trying to auto-scale beyond the quota.
Further, if a quota is set on a namespace, all pods must have resource requests/limits specified or the scheduling of that pod will fail.
This is yet another reason why clear communication between development and cloud ops is essential.
Other Isolation Policies
IBM Cloud Private has support for many levels of multi-tenancy. This includes the ability to control workload deployments to specific resources like worker nodes, VLANs, network firewalls, and more based on teams and namespaces.
Have I mentioned that your development team needs to have clear communication with your cloud ops team? I think so.
Here is a summary of what you should consider when auto-scaling your application. The actual numbers may vary based on your application, so use this as guide.
- As you initially create your microservice, give your resource requests/limits a sensible default. This could vary greatly depending on your base image, runtime, etc. For example, for Liberty runtimes, set it between 200m and 1000m for CPU, and 128Mi and 512Mi to Memory. If you set the limits too low, the autoscaler may trigger an additional instance during initial startup because it’s taking too much CPU.
- Run initial unit tests and use Grafana monitoring to see actual CPU and Memory usage during your tests.
- Refine your resource requests/limits as needed so your resource limits are 20% more than monitored maximum usage.
- Set your initial auto-scale policy to scale your application at 50% of CPU usage.
- If you use Istio, increase all resource limits by 100m CPU and 128Mi Memory to handle the additional side-car.
- Work with your cloud ops team if any affinity rules or resource quotas will be in place in the clusters across your stages of delivery: development, test, stage, production.
Note: For classic WebSphere applications that you migrated into containers using Transformation Advisor, you may not be able to auto-scale. That said you should still create good liveness and readiness probes and set your resource request/limits.
Next time we will step through how that best practice is set up using Liberty-based microservices.
OK! Thanks for reading and keep on the lookout for Part 2 coming soon!
lqwzxe